
Now, I am a Research Scientist (Field of Large Speech Model) in ByteDance ![]() . I graduated from the Department of Computer Science, Zhejiang University (浙江大学计算机科学与技术学院), advised by Zhao Zhou (赵洲). Before that, I graduated from Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院).
. I graduated from the Department of Computer Science, Zhejiang University (浙江大学计算机科学与技术学院), advised by Zhao Zhou (赵洲). Before that, I graduated from Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院).
My research interest includes speech & singing synthesis, avatar, and machine translation. I have published over 30 papers at the top international AI conferences such as NeurIPS, ICLR, ICML, AAAI, ACL, with total google scholar citations 
I served as reviewers in EMNLP 21&22, ICML 22, NeurIPS 22&23, ICLR 24, ICASSP 23&24, ACL 23, NAACL 24, TASLP etc.
Previously, I worked as a research intern at Alibaba DAMO Academy ![]() , and ByteDance SAMI
, and ByteDance SAMI ![]() . I used to have academic cooperation with Microsoft Research Asia
. I used to have academic cooperation with Microsoft Research Asia ![]() .
.
My selected open-source projects: DiffSinger 

!
My selected project @ ByteDance: MegaTTS 2.
🔥 News
- 2024.01: Two papers are accepted by ICLR 2024!
- 2023.05: Six papers are accepted by ACL 2023!
- 2023.04: One paper is accepted by ICML 2023!
- 2023.01: Two papers are accepted by ICLR 2023!
- 2022.09: Three papers are accepted by NeurIPS 2022!
- 2022.02: One paper is accepted by ACL 2022!
📝 Publications
Selected Papers
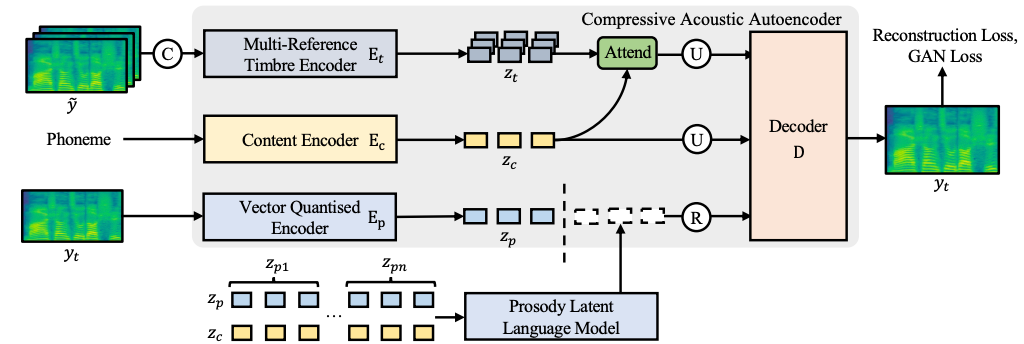
MegaTTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu*, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun MA, Zhou Zhao; ![]() & ZJU
& ZJU
- Brief Introduction: Large Text-to-Speech Model.
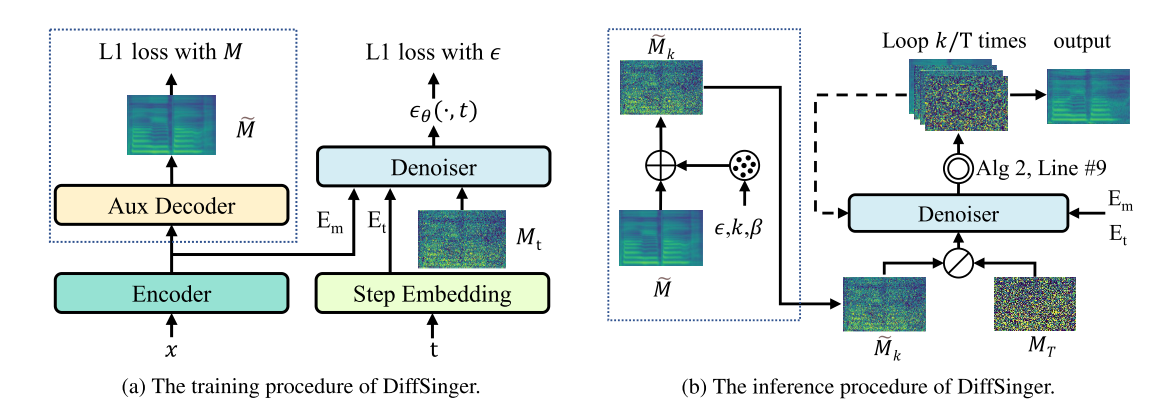
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, Zhou Zhao
Project | 
|
- Brief Introduction: This paper contains the first acoustic models based on diffusion, including DiffSinger (SVS) and DiffSpeech (TTS). It realizes the high-quality speech/singing synthesis.
- DiffSinger & DiffSpeech have recieved
 .
. - Many video demos created by Bilibili creators are released. And Diffsinger is introduced by a very popular video
!
- This work is included by many famous speech/music synthesis open-source projects, such as ESPNet
, PaddlePaddle/Parakeet
, muzic
.
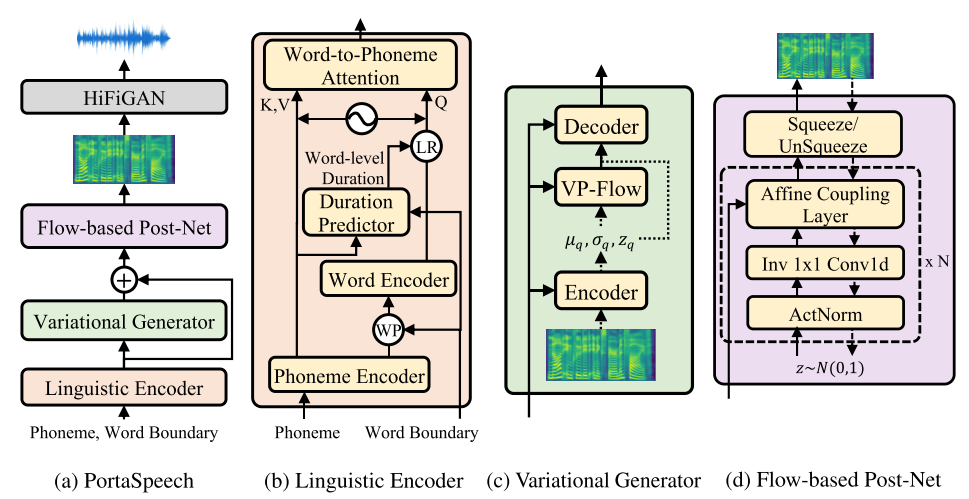
PortaSpeech: Portable and High-Quality Generative Text-to-Speech
Yi Ren*, Jinglin Liu*, Zhou Zhao
Project | 
- The source codes of this paper are released together with the codes of DiffSpeech. This repository has received
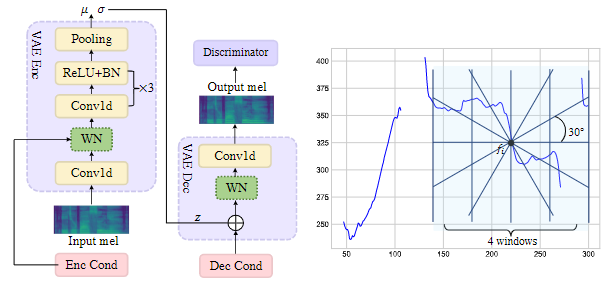
Learning the Beauty in Songs: Neural Singing Voice Beautifier
Jinglin Liu, Chengxi Li, Yi Ren, Zhiying Zhu, Zhou Zhao
Project | 

Recent Papers
- Ziyue Jiang*, Jinglin Liu*, Yi Ren*, Jinzheng He*, Chen Zhang, Zhenhui Ye, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao, Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis, ICLR 2024 (* equal contributions)
- Jinglin Liu*, Zhenhui Ye*, Qian Chen, Siqi Zheng, Wen Wang, Qinglin Zhang, Zhou Zhao, DopplerBAS: Binaural Audio Synthesis Addressing Doppler Effect, ACL 2023. (* equal contributions)
- Jinzheng He, Jinglin Liu, Zhenhui Ye, Rongjie Huang, Chenye Cui, Huadai Liu, Zhou Zhao, RMSSinger: Realistic-Music-Score based Singing Voice Synthesis, ACL 2023
- Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, Zhou Zhao, Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models, ICML 2023
- Rongjie Huang*, Jinglin Liu*, Huadai Liu*, Yi Ren, Lichao Zhang, Jinzheng He, Zhou Zhao, TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation, ICLR 2023. (* equal contributions)
- Zhenhui Ye, Ziyue Jiang, Yi Ren, Jinglin Liu, Jinzheng He, Zhou Zhao, GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis, ICLR 2023
- Ziyue Jiang, Zhe Su, Zhou Zhao, Qian Yang, Yi Ren, Jinglin Liu, Zhenhui Ye, Dict-TTS: Learning to Pronounce with Prior Dictionary Knowledge for Text-to-Speech, NeurIPS 2022
- Rongjie Huang, Yi Ren, Jinglin Liu, Chenye Cui, Zhou Zhao, GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech, NeurIPS 2022
- Jinglin Liu, Chengxi Li, Yi Ren, Zhiying Zhu, Zhou Zhao, Learning the Beauty in Songs: Neural Singing Voice Beautifier, ACL 2022
- Jinglin Liu*, Chengxi Li*, Yi Ren*, Feiyang Chen, Zhou Zhao, DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism, AAAI 2022. (* equal contributions)
- Yi Ren*, Jinglin Liu*, Zhou Zhao, PortaSpeech: Portable and High-Quality Generative Text-to-Speech, NeurIPS 2021. (* equal contributions)
- Jinglin Liu, Zhiying Zhu, Yi Ren, Wencan Huang, Baoxing Huai, Nicholas Jing Yuan, Zhou Zhao, Parallel and High-Fidelity Text-to-Lip Generation, AAAI 2022
- Jinglin Liu, Yi Ren, Zhou Zhao, Chen Zhang, Baoxing Huai, Jing Yuan, FastLR: Non-Autoregressive Lipreading Model with Integrate-and-Fire, ACM-MM 2020
- Jinglin Liu, Yi Ren, Xu Tan, Chen Zhang, Tao Qin, Zhou Zhao and Tie-Yan Liu, Task-Level Curriculum Learning for Non-Autoregressive Neural Machine Translation, IJCAI 2020
- Yi Ren*, Jinglin Liu*, Xu Tan, Chen Zhang, Qin Tao, Zhou Zhao, Tie-Yan Liu, SimulSpeech: End-to-End Simultaneous Speech to Text Translation, ACL 2020. (* equal contributions)
- Yi Ren*, Jinglin Liu*, Xu Tan, Zhou Zhao, Sheng Zhao, Tie-Yan Liu, A Study of Non-autoregressive Model for Sequence Generation, ACL 2020. (* equal contributions)
My full paper list is shown at my scholar homepage.
📄 Services
- Program Committee and Paper Reviewer: EMNLP (2021, 2022), ICML (2022), NeurIPS (2022,2023), ICLR (2024), ICASSP (2023, 2024), ACM-MM (2023), ACL (2023), TASLP (2023).
💻 Industrial Experience
- 2023.05 - Now, ByteDance, Research Scientist.
- 2022.07 - 2023.02, Alibaba, Research Intern.
- 2021.06 - 2021.09, ByteDance, Research Intern.
🎖 Honors and Awards
- 2023.01 Outstanding Graduate of Zhejiang Province
- 2023.01 Outstanding Graduate of ZJU
- 2022.12 Runner-up in China Graduate AI Innovation Competition (2/1217)
- 2022.10 National Scholarship (Top 1%)
- 2021.10 National Scholarship (Top 1%)
- 2021.10 Tencent Scholarship (Top 1%)
- 2020.06 Excellent Undergraduate Thesis of ZJU
- 2020.06 Outstanding Graduate of ZJU
📖 Educations
- 2020.06 - 2023.03, Master, Zhejiang University, Hangzhou.
- 2016.09 - 2020.06, Undergraduate, Chu Kochen Honors College, Zhejiang Univeristy, Hangzhou.
💬 Invited Talks
- 2022.02, Audio Synthesis and Re-Synthesis, at MLNLP seminar | [Video]